Forecast sales system for an airline company, part II: service forecasting bookings by ML
Intro
This a 2nd publication regarding building forecast sales system for
an airline company which covers ML models and infrastructure to run it.
Tech stack is: Kafka, neuralforecast, pytorch-lightning, python, pydantic, sqlalchemy, asyncio, pytest, mypy, postgress.
Tech stack is: Kafka, neuralforecast, pytorch-lightning, python, pydantic, sqlalchemy, asyncio, pytest, mypy, postgress.
The nature and the structure of data
The ultimate goal of the project is to get all business data and
based on this forecast sales of flights tickets. The important
point is it should work better rather than current popular solutions
which left Russian market due political restrictions enforced by USA.
The data business is able to offer is a history of bookings over several years. It includes:
In terms of the math and the ML we have a fluctuation of value which should be predicted for a future time interval. Because data has multiple fields to predict, the task become more complex.
The data business is able to offer is a history of bookings over several years. It includes:
- Flight number
- Date of departure
- Route: departure and destination airport
- Cost of the ticket
- Booking class (one from 25 possible items)
- And many more
In terms of the math and the ML we have a fluctuation of value which should be predicted for a future time interval. Because data has multiple fields to predict, the task become more complex.
ML model
There is a special class of machine learning models which operates
with time-series data. This is our case because our goal is to
predict an amount on bookings in the future based on actual
bookings in the past.
Such kind of models are good in prediction of seasonality and trends which is crucial in sales.
Often data is smoothed to reduce impact of the noise and figured out an useful data.
The simplest model predicts one variable over time. However in our case we have a tuple of variables 'flight number' - 'date' - 'cabin' - 'booking class'. In the first iteration during decomposition of the task the ML team ended up with a single model per tuple which gives us near 40 000 models (1600 flights x 25 booking classes).
Architecture of the ML model looks like this:
- AutoCorrelation layer which spot period-based dependencies and does time-delay aggregation
- LayeredNorm layer to spot seasonal part
- MovingAverage layer to spot trends
- SeriesDecomposition layer
- EncoderLayer
- DecoderLayer
- Autoformer
Aggregating ML models into codebase has their own challenges. At first, besides model you have to store hyperparameters which define model's work. At second, work of models depends on the data (train, test, validate) which is also good to save and versioning. At third, work on ML models implies multiple try&run iterations which gives a set of different versions of the same model which sometimes necessary to store simultaneously. The market offer a special class of such solutions called ML Registry.
Quick research shown mlflow as the best suitable for project's requirements. However despite on its rich functionality, it is a bit overkill for a current state of the project. We ended up to store the actual implementation of the model within codebase and the rest work to leave in a separate repository.
Such kind of models are good in prediction of seasonality and trends which is crucial in sales.
Often data is smoothed to reduce impact of the noise and figured out an useful data.
The simplest model predicts one variable over time. However in our case we have a tuple of variables 'flight number' - 'date' - 'cabin' - 'booking class'. In the first iteration during decomposition of the task the ML team ended up with a single model per tuple which gives us near 40 000 models (1600 flights x 25 booking classes).
Architecture of the ML model looks like this:
- AutoCorrelation layer which spot period-based dependencies and does time-delay aggregation
- LayeredNorm layer to spot seasonal part
- MovingAverage layer to spot trends
- SeriesDecomposition layer
- EncoderLayer
- DecoderLayer
- Autoformer
Aggregating ML models into codebase has their own challenges. At first, besides model you have to store hyperparameters which define model's work. At second, work of models depends on the data (train, test, validate) which is also good to save and versioning. At third, work on ML models implies multiple try&run iterations which gives a set of different versions of the same model which sometimes necessary to store simultaneously. The market offer a special class of such solutions called ML Registry.
Quick research shown mlflow as the best suitable for project's requirements. However despite on its rich functionality, it is a bit overkill for a current state of the project. We ended up to store the actual implementation of the model within codebase and the rest work to leave in a separate repository.
Service that runs this model
General overview
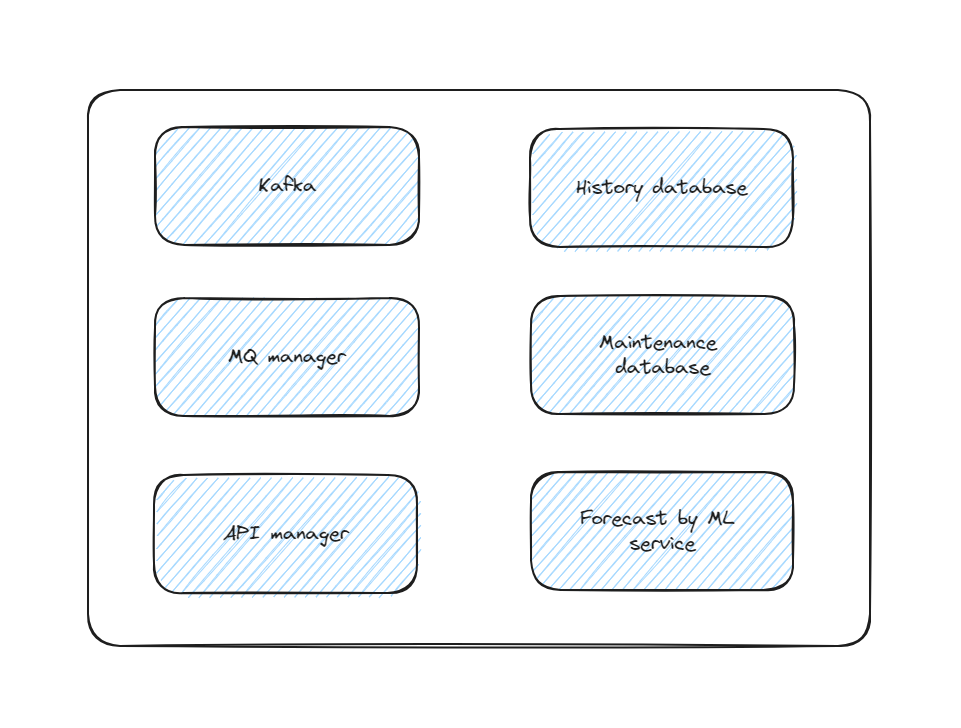
The model which forecast bookings is a core of the system. The first iteration of the project actually has two models -- one is based on a machine learning and another one is based on a classic math. They are used as two approaches to solve the same task as a part of R&D.
The source of the data is customer's inventory system which is based on the Kafka. Kafka's topics with high-frequency are populated with new bookings. The one of our services listens a group of Kafka's topics, receives and parse data finally saving it in several tables where key two are flights and flights data where the 1st represent a flight and the 2nd is recently made orders. Database with this tables is replicated - the first database contains all actual flights which are going to happen and the second database contains flights which has been happened already. As soon as a flight departed from an airport, this flight's data is moved from the one database to the another database.
Later by schedule this data is queried and passed to a model to build forecasts. The results are saved in the database for a future usage. The future work with this data is done over a API service.
To make it clear: we have Kafka which is served as a message queue, we have a history and a maintenance databases, a service which runs forecasts by ml and math models by schedule, the API REST web service which provides access to this data.
Each of this services is run in the docker container aggregated over a docker compose with future plans to migrate on kubernetes.
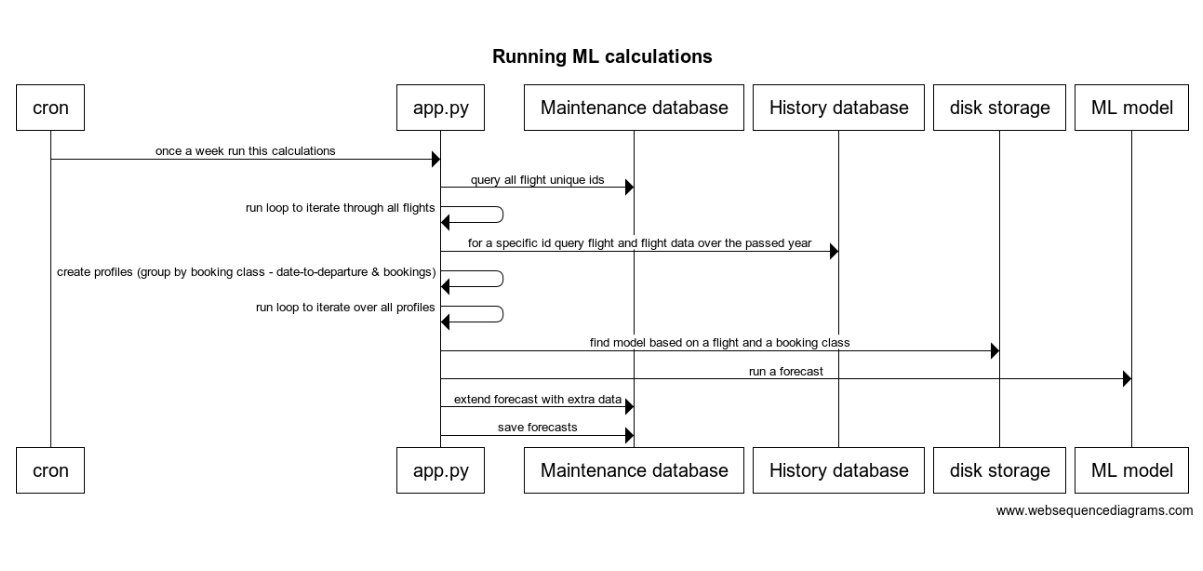
Cron once a week run this calculations Application queries all flights unique ids from the 1st database and iterate through all flights. For a specific id it query flights and flights data over the passed year from the 2nd database. After this it creates profiles (group by booking class - date-to-departure & bookings) and iterate over all profiles.
Based on a flight and a booking class it reverse engineer cabin and find model on the disk by iterating names of folders. When a model and input data are here it runs a forecast. Results of the forecast are extended with extra data and saved into the 1st database.
Everything is packed into the Dockerfile.
Clean architecture principles and the pythonic way
Python is known as a multi paradigm language and it is important
to write on the each language in a way which is natural for them.
However quick research shown no breaks in my UX -- in short
everywhere you expect to use OOP principles they should be used.
Principles of the clean architecture fit Python projects as well making it clear layered and low coupled.
Principles of the clean architecture fit Python projects as well making it clear layered and low coupled.
Prepare the data: dealing with a large dataset
This is my first project where I have to deal with more than
one billion records. Challenges I met and solutions I had
found is covered by
this publication
Grouping the data and dataframe
Data which has been extracted from flights and flights data
tables should be grouped in a special manner before being passed
to a ML model. Technically we have to prepare a dictionary of booking
classes served as keys where values are lists of dates and
bookings on each date.
It is done over DataFrame.
I am fascinated about a power of the panda's DataFrame. It allows to do a lot of things on sophisticated data structures and at the same time it can be used as an input and return parameters.
data = {
'E': ([1, 2, 3], [1.0, 2.0, 6.0]),
'G': ([1, 2, 3], [2.5, 2.5, 3.0]),
'L': ([1, 2, 3], [2.5, 3.5, 3.0]),
'O': ([1, 2, 3], [3.0, 3.5, 3.5])
}
It is done over DataFrame.
I am fascinated about a power of the panda's DataFrame. It allows to do a lot of things on sophisticated data structures and at the same time it can be used as an input and return parameters.
Parallelization, coroutines and GIL
Python language design has such thing like a global interpreter
locker (GIL) which acts as a mutex limiting performance gains
from multithread operations for CPU-bound tasks. However for
IO-bound tasks it is not an issue. It means creating a thread
or coroutine on python wouldn't give you results which you
expect when you do the same on others languages.
A workaround for this is to spawn an another process instead of the thread. It overcomes GIL limitations on python and gives you a parallelization.
It was nice to see, besides others instruments for concurrent execution of the program, Python supports coroutines over asyncio library. It looks as a superior solution for multithreading tasks.
A workaround for this is to spawn an another process instead of the thread. It overcomes GIL limitations on python and gives you a parallelization.
It was nice to see, besides others instruments for concurrent execution of the program, Python supports coroutines over asyncio library. It looks as a superior solution for multithreading tasks.
Test coverage
Test coverage is done over pytest. With some nuances which
makes each framework unique it works in the similar way like
the rest testing frameworks I have worked so far.
Despite on TDD is a superior way to develop software, with limited time I cover by tests main execution scenarios and write a unit test per bug which has been discovered. It allows verification of the software in an automatic way and confirm issues has been made in the past are fixed and do not repeat.
Despite on TDD is a superior way to develop software, with limited time I cover by tests main execution scenarios and write a unit test per bug which has been discovered. It allows verification of the software in an automatic way and confirm issues has been made in the past are fixed and do not repeat.
Scheduling
Such calculations of forecasts should be done by a schedule.
Ideally when new critical amount of the data comes, forecasts
should be recalculated. However client doesn't ended up with a
decision yet how much new data is considered enough to schedule
recalculations, so we just run this service by schedule, e.g.
each Sunday midnight.
Cron has been chosen as a schedule solution. Cron is a native for linux systems; simple, but powerful it covers all current needs of the project. It is even supported out-of-the-box in kubernetes which would be helpful when the team will decide to migrate on it.
However right now I run it from Dockerfile and it has some caveats.
Cron changes context of the execution of the code it launches. In my case it had made all env variable unavailable and I had to source them explicitly from the initialization shell script.
Also it had made external volume mapped to a container unavailable and I had not managed this issue yet. As a workaround I cloned all required files into the repo directly and a create a 'base image' to avoid frequent recreation of this less often changing piece of the logic. It made solution less elegant rather than the initial one, but still workable and production ready.
Cron has been chosen as a schedule solution. Cron is a native for linux systems; simple, but powerful it covers all current needs of the project. It is even supported out-of-the-box in kubernetes which would be helpful when the team will decide to migrate on it.
However right now I run it from Dockerfile and it has some caveats.
Cron changes context of the execution of the code it launches. In my case it had made all env variable unavailable and I had to source them explicitly from the initialization shell script.
Also it had made external volume mapped to a container unavailable and I had not managed this issue yet. As a workaround I cloned all required files into the repo directly and a create a 'base image' to avoid frequent recreation of this less often changing piece of the logic. It made solution less elegant rather than the initial one, but still workable and production ready.
Challenges to deal with multiple repositories and large files in git
The project is scattered among several repositories. To make it
run smooth we have to do some extra steps. Repo sync seems like
the right tool to do this. It is based on the git and allows
operates with your repositories in the unified way.
Another issue is ML models stored in git. There are many of them and they stored a big amount of the space. Git is not designed for this: tracking all of them and a history (!) of their changes will make further work wit h git unconvenient.
Git LFS is a solution for it. It is an extension for Git that replaces large files in your repository with text pointers while storing the file contents on a remote server. This keeps your repository lean while still allowing you to manage large files.
This task is not implemented yet and stored in the backlog.
Another issue is ML models stored in git. There are many of them and they stored a big amount of the space. Git is not designed for this: tracking all of them and a history (!) of their changes will make further work wit h git unconvenient.
Git LFS is a solution for it. It is an extension for Git that replaces large files in your repository with text pointers while storing the file contents on a remote server. This keeps your repository lean while still allowing you to manage large files.
This task is not implemented yet and stored in the backlog.
Mitigate docker blocks risks
The work and support of the project may be blocked in case of
politically forced blocking of the docker ecosystem.
At the end of May 2024, we encountered the fact that docker repositories and servers were blocked for users from the Russian Federation.
A possible solution to this problem is to set up your own internal repository from which to download docker images or to pass a proxy to bypass restrictions.
Proxy passing, and even using docker images as is, opens up a security attack vector associated with introducing malware into images (supply chain attack). Docker provides a service for automatic image checking, but it is not free, and it will be even more difficult with the next politically justified blocking of the docker ecosystem.
When setting up your own internal repository, this check will also need to be done on your own.
At the end of May 2024, we encountered the fact that docker repositories and servers were blocked for users from the Russian Federation.
A possible solution to this problem is to set up your own internal repository from which to download docker images or to pass a proxy to bypass restrictions.
Proxy passing, and even using docker images as is, opens up a security attack vector associated with introducing malware into images (supply chain attack). Docker provides a service for automatic image checking, but it is not free, and it will be even more difficult with the next politically justified blocking of the docker ecosystem.
When setting up your own internal repository, this check will also need to be done on your own.
How to deal with a lack of the static typed?
The lack of the static typed became a serious issue. Especially after
change requests and refactoring I started to get unexpected types of
data in methods. Something which never happened on Java or Kotlin.
Several steps had been made to solve this issue.
Several steps had been made to solve this issue.
Migrate on pyndatic models
Pydantic models allows you to define a model of your data and
at the same time enforce an automatic validation of data fields.
It was a good first step to sanitize your data types.
Defensive programming
The next step was an applying defensive programming techniques.
It means checking types of input data within the function. Such
technique helped a lot t quickly spot all current and potential
issues.
Static analyzer mypy
Python ecosystem also offer a mypy -- static analyzer of your
code which points out where you get data with type different
from what you has defined previously. It gives the most
comprehensive solution to spot issues with your code data
types.
Related publications:
Forecast sales system for an airline company, part I: working with one billion records
Docker based Kafka - Kafka Connect - PostgreSQL pipeline with automatic export data from queue to database with REST server on Python to read this data. Intended for needs of the airline.
Case study: automatic Chinese text word segmentation and translation
Case study: ML. Housing price prediction