Case study: building Kafka - Kafka Connect - PostgreSQL data pipeline with a REST API on Python for an airline
Executive summary
Over passed week I learned a new tech stack and built a PoC for the airline
which is data pipeline for their stream of upcoming flights. The project is
based on Kafka, Kafka Connect and PostgreSQL with a REST server on
Python. Everything containerized in Docker and deployed over
Docker Compose.
Apache Kafka is an open source solution for a message queue which is
designed to be robust, fault-tolerant and easily scaled up in
response to quick growth of upcoming data.
Kafka Connect is a solution to integrate Kafka with many data
sources and data storages by just providing configuration file.
Then Kafka would automatically upload and export data to & out the queue
from & to specified source and sink databases.
PostgreSQL is just one more database which fits better my potential
customer needs.
Not Everything went smoothly. Kafka migrates from Zookeeper to KRaft
- internal mechanisms used by Kafka to manage its state - which
caused me some issues and pivot the project from pure
apache/kafka to confluentinc/kafka implementation which has an offer
of its code under acceptable open source license.
This is a first project where I had used ChatGPT to configure Kafka,
write backend on Python and also to write this publication. It speed
up process of learning a new tech
stack on at least 50%. It is good for search, it is very good in
refactoring code, it is good in code review. It is not good in
fully writing software, it could not (yet) fully replace your
experience. It still can not avoid mistakes. Despite on ChatGpt is
a good aid as an expert system for a software engineer, its future
impact on a software industry is hazy - it my cause engineers rely
more on technology rather than on their own knowledge and skills
which would cause degradation of their qualification.
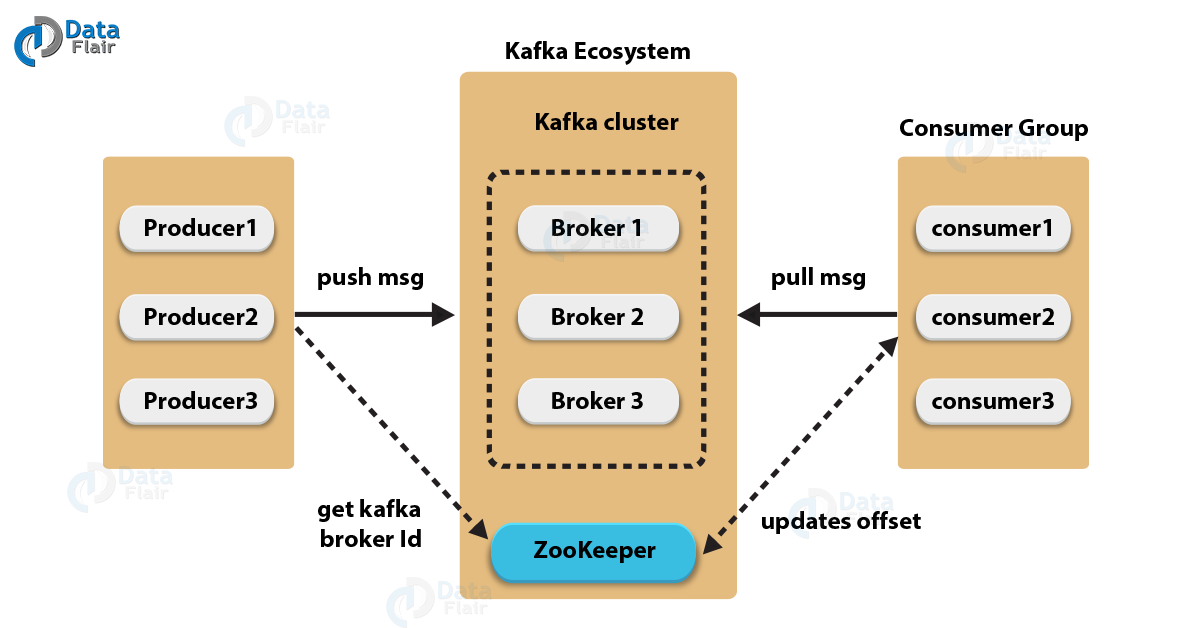
Whats is an Apache Kafka?
1. Kafka Connect Architecture Overview
- Kafka Connect Cluster: The core system for managing connectors and workers.
- Connectors: Plugins that manage data transfer between Kafka and other systems.
- Source Connectors: Import data from external systems into Kafka topics.
- Sink Connectors: Export data from Kafka topics to external systems.
- Workers: Instances of Kafka Connect that execute the connectors.
- Standalone Mode: Single worker instance, suitable for development and testing.
- Distributed Mode: Multiple worker instances for load balancing and fault tolerance.
2. Data Flow in Kafka Connect
Source System -> Source Connector -> Kafka Topic -> Sink Connector -> Target System
3. Components in Detail
Connectors:
- Source Connector: Reads data from a source system (e.g., a database, file system, or an application) and writes it to a Kafka topic.
- Sink Connector: Reads data from a Kafka topic and writes it to a target system (e.g., a database, file system, or another application).
- Standalone Worker: A single process that runs both source and sink connectors.
- Distributed Workers: Multiple processes that share the workload of connectors, providing scalability and fault tolerance.
4. Connector Configuration
Connector Configuration:
- Defines how data is read from or written to external systems.
- Contains properties like connection details, data format, and transformation rules.
5. Task Distribution
In a distributed setup, the data processing tasks are split among workers:
- Worker 1:
- Executes Task 1 (Source Connector Part)
- Executes Task 2 (Sink Connector Part)
- Worker 2:
- Executes Task 3 (Source Connector Part)
- Executes Task 4 (Sink Connector Part)
6. Offset Management
Kafka Connect manages the state of data processing using offsets:
- Source Connector: Tracks the position in the source system to ensure data is not missed or duplicated.
- Sink Connector: Tracks the position in Kafka topics to ensure data is processed sequentially.
7. Transformations
Kafka Connect can apply transformations to data as it passes through:
- Single Message Transforms (SMTs): Modify individual messages (e.g., filter, rename fields, change formats) before they reach the destination.
8. Monitoring and Management
Kafka Connect provides tools for monitoring and managing connectors and workers:
- REST API:
- Allows management of connectors (start, stop, configure) and workers.
- Provides metrics and status information.
- UI Tools: Many Kafka distributions include web interfaces for managing Kafka Connect.
9. Error Handling
Kafka Connect includes mechanisms for handling errors:
- Dead Letter Queues: Messages that cannot be processed are sent to a separate Kafka topic for later analysis.
- Retry Policies: Configurations that determine how many times a connector should retry a failed operation before giving up.
Apache Kafka Connect
1. Kafka Connect Architecture Overview
Kafka Connect Cluster: The core system for managing connectors and workers.
Connectors: Plugins that manage data transfer between Kafka and other systems.
- Source Connectors: Import data from external systems into Kafka topics.
- Sink Connectors: Export data from Kafka topics to external systems.
- Standalone Mode: Single worker instance, suitable for development and testing.
- Distributed Mode: Multiple worker instances for load balancing and fault tolerance.
2. Data Flow in Kafka Connect
Source System -> Source Connector -> Kafka Topic -> Sink Connector -> Target System
Visualize the data flow through connectors and workers.
3. Components in Detail
Connectors:
- Source Connector: Reads data from a source system (e.g., a database, file system, or an application) and writes it to a Kafka topic.
- Sink Connector: Reads data from a Kafka topic and writes it to a target system (e.g., a database, file system, or another application).
- Standalone Worker: A single process that runs both source and sink connectors.
- Distributed Workers: Multiple processes that share the workload of connectors, providing scalability and fault tolerance.
4. Connector Configuration
Connector Configuration: Defines how data is read from or written to external systems.
Contains properties like connection details, data format, and transformation rules.
5. Task Distribution
In a distributed setup, the data processing tasks are split among workers:
- Worker 1: Executes Task 1 (Source Connector Part), Executes Task 2 (Sink Connector Part)
- Worker 2: Executes Task 3 (Source Connector Part), Executes Task 4 (Sink Connector Part)
6. Offset Management
Kafka Connect manages the state of data processing using offsets:
- Source Connector: Tracks the position in the source system to ensure data is not missed or duplicated.
- Sink Connector: Tracks the position in Kafka topics to ensure data is processed sequentially.
7. Transformations
Kafka Connect can apply transformations to data as it passes through:
- Single Message Transforms (SMTs): Modify individual messages (e.g., filter, rename fields, change formats) before they reach the destination.
8. Monitoring and Management
Kafka Connect provides tools for monitoring and managing connectors and workers:
- REST API: Allows management of connectors (start, stop, configure) and workers. Provides metrics and status information.
- UI Tools: Many Kafka distributions include web interfaces for managing Kafka Connect.
9. Error Handling
Kafka Connect includes mechanisms for handling errors:
- Dead Letter Queues: Messages that cannot be processed are sent to a separate Kafka topic for later analysis.
- Retry Policies: Configurations that determine how many times a connector should retry a failed operation before giving up.
Integration
Basically, besides Kafka itself there are Zookeeper to manage its
state, PostgreSQL database to export data from the message queue,
Kafka Connect to make this automatically, data source which for
this PoC a service on Python, REST server -- that is all should be
integrated with each other.
System parts which could be integrated with Kafka are called source
- place from where data come to the Kafka, - or sink -- place where data
from Kafka are mirrored.
Kafka Connect allows to automatically import and export data by
defining just a configuration file which looks like this:
{
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "Topic_Name",
"connection.url": "jdbc:postgresql://postgres:5432/db_name",
"connection.user": "username",
"connection.password": "pwd",
"auto.create": "true",
"insert.mode": "upsert",
"pk.mode": "record_value",
"pk.fields": "flight,flight_booking_class",
"driver.class": "org.postgresql.Driver",
"plugin.path": "/usr/share/java,/usr/share/confluent-hub-components",
"errors.log.enable": "true",
"errors.log.include.messages": "true"
}'
The file is a self-explanatory, but it worth to comment a few things. Topics property represents storage name where data in Kafka exist. You might think about it as a table\tables names.
PK fields are primary keys of the tables data from Kafka goes to.
Personally I found importance of defining CLASSPATH here. Confluent implementation of Kafka still relies on CLASSPATH in some cases, despite on it is a legacy mechanism.
Besides config of integration with sink\source databases Kafka Connect should know Kafka backend endpoint, advertise IP address which others could reach this service and amount of replicas for key datasets which should be aligned to the number of brokers in system. Here is how Kafka Connect is defined as a docker service:
connect:
image: confluentinc/cp-kafka-connect:6.2.0
container_name: connect
hostname: connect
depends_on:
- kafka
- postgres
ports:
- "8083:8083"
environment:
CONNECT_BOOTSTRAP_SERVERS: "kafka:9092"
CONNECT_REST_ADVERTISED_HOST_NAME: 172.16.254.4
CONNECT_GROUP_ID: connect-cluster
CONNECT_CONFIG_STORAGE_TOPIC: _connect-configs
CONNECT_OFFSET_STORAGE_TOPIC: _connect-offsets
CONNECT_STATUS_STORAGE_TOPIC: _connect-status
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_PLUGIN_PATH: /usr/share/java,/usr/share/confluent-hub-components
CONNECT_REPLICATION_FACTOR: 1
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CLASSPATH: /usr/share/java/postgresql-42.2.23.jar:/usr/share/confluent-hub-components/kafka-connect-jdbc-10.7.6.jar
volumes:
- ./kafka-connect/connectors:/usr/share/confluent-hub-components
- ./kafka-connect/config:/etc/kafka-connect
- ./kafka-connect/postgresql-42.2.23.jar:/usr/share/java/postgresql-42.2.23.jar
networks:
priv-net:
ipv4_address: 172.16.254.4
Kafka's service important env properties include broker id, endpoint
to communicate with a zookeeper, advertising endpoints for internal
and external communication with Kafka's service. Here is how it is
defined it docker service:
kafka:
image: confluentinc/cp-kafka:6.2.0
hostname: kafka
container_name: kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://172.16.254.3:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
networks:
priv-net:
ipv4_address: 172.16.254.3
healthcheck:
test: ["CMD", "sh", "-c", "exec nc -z localhost 9092"]
interval: 10s
timeout: 10s
retries: 5
KRaft is a preferable mechanism to use instead of
Zookeeper, although the current Kafka release
(apache/kafka:3.7.0) still rely on Zookeeper. We have to
use Zookeeper right now, but in the next release
Kafka 4.0 it is going to be removed. Unfortunately,
in apache/kafka I faced with some bizarre issue related to
conflict between Zookeeper and KRaft which I have not resolved yet.
This caused pivot of the project towards docker images from
Confluent Inc, they are under acceptable open source license, so
it is safe to use it. Here is Zookeeper docker service:
zookeeper:
image: confluentinc/cp-zookeeper:6.2.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
networks:
priv-net:
ipv4_address: 172.16.254.2
The rest docker services are available
in project's repository.
Backend
Backend doesn't have something special to share and serves as a
REST endpoint to view data. It is available in repository by
this link.
It is also packed in the docker and deployed as a service over a
docker compose.
Data producer
This project uses a PostgreSQL as a sink storage for data from Kafka,
but there is no source database. Instead another service called
producer writes this data to Kafka topic.
Integration with Kafka is done over special library and looks like
this:
self.producer = KafkaProducer(
bootstrap_servers=[f"{self.kafka_host}:{self.kafka_port}"],
value_serializer=self.serializer
)
new_event = generate_inventory()
self.producer.send(self.kafka_topic, new_event).add_callback(self.on_send_success).add_errback(self.on_send_error)
Worth to note business specific aspect of the data. Airline
inventory data looks like this:
"schema": {
"type": "struct",
"fields": [
{"type": "int64", "optional": False, "field": "time"},
{"type": "string", "optional": False, "field": "flight"},
{"type": "int64", "optional": False, "field": "departure"},
{"type": "string", "optional": False, "field": "flight_booking_class"},
{"type": "int32", "optional": False, "field": "idle_seats_count"}
],
"optional": False,
"name": "InventorySchema"
},
Flight booking class has 25 (!) possible variants:
flight_booking_class = [
"F", "A", "P", "R", "I", "D", "Z", "C", "J", "W",
"S", "Y", "B", "H", "K", "L", "M", "N", "Q", "T",
"V", "G", "X", "E", "U"
]
I don't remember what each of them means, but every type represents
a unique business offer which airline prepare for their customers
which direct impact on the final cost of the airplane ticket. In regard to integration Kafka Connect requires a schema to be passed with a message to a topic.
Producer service also packed into docker container, deployed together with the rest of the system and randomly generates a sample inventory each 1 to 7 seconds.
The full code is available under this link A few related publications:
[source code] Docker based Kafka - Kafka Connect - PostgreSQL pipeline with automatic export data from queue to database with REST server on Python to read this data. Intended for needs of the airline.
Docker: multicomponent project deployment
Swap tech notes, part 4: automatization