Swap tech notes, part 3: server and mobile clients
Intro
This is a third part of the seria of publications regarding work on the Swap project. It covers a work on server and mobile clients.
Swap v1 -> Swap v2 migration
The first iteration of the project covered a client-server application
with common marketplace business logic which was extended by smart
contracts.
When work on smart contracts had been done and project had been
deployed into the test mode, the test drive shown extra overhead in
gas. Gas is a limited resource which is necessary to run operations on
the chain. Also it costs real money. This pilot shown launching this
product on the real ethereum chain never will be profitable.
The issue is such operations like iteration over a dataset are very
costly in terms of gas/money. With dataset growth the cost of
platform exploitation will grow too. There are options to optimize
gas usage, but it will reduce by tens of percent, but project
requires to reduce it at times less.
To overcome this issue two things had been made.
The first one is to limit business logic in smart contracts to the
most important one - (mostly) unreversible data records. Smart
contracts had been refactored to leave a mint a token, an exchange of
tokens and an approval of intentions functionality on chain. The rest
will be done on the server.
This step significantly reduces gas usage and makes project's smart
contracts looks like what is deployed on the real chain, but still
it leaves open issue of profitability of the product.
The second step is to launch product within a private chain. Deploying
a private chain will give us control on the gas cost (~0 USD),
difficulty to mine a new block and, therefore, time to wait when
transaction will be completed. It solves our issues discovered
during the 1st pilot and gives chances for ethereum ledger to be
used in this project.
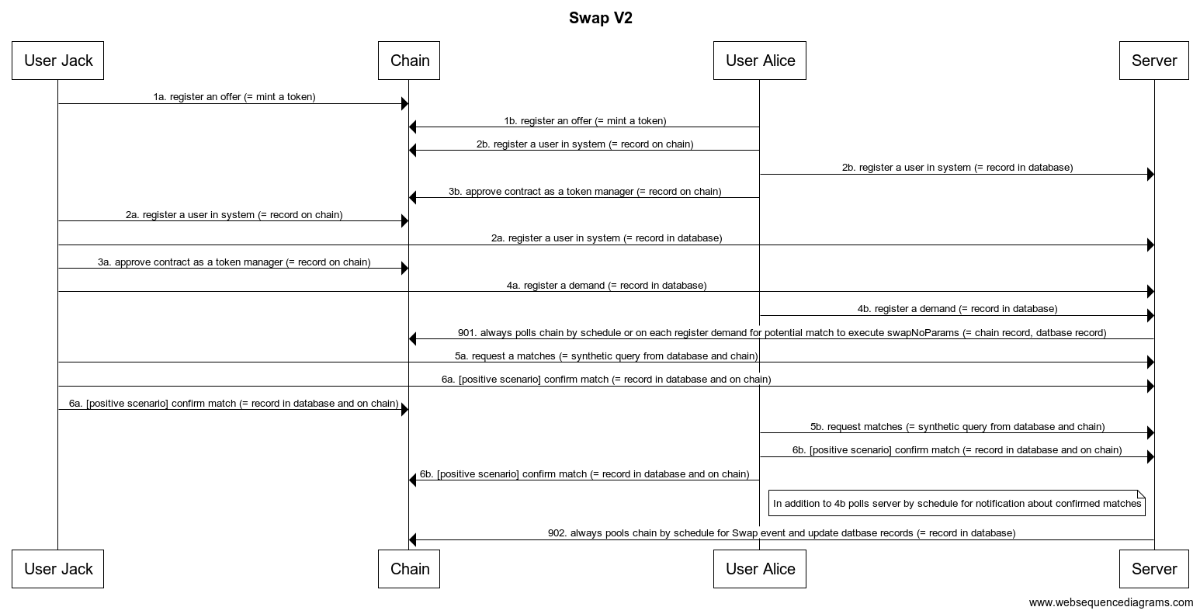
Swap v2 state sequence diagram
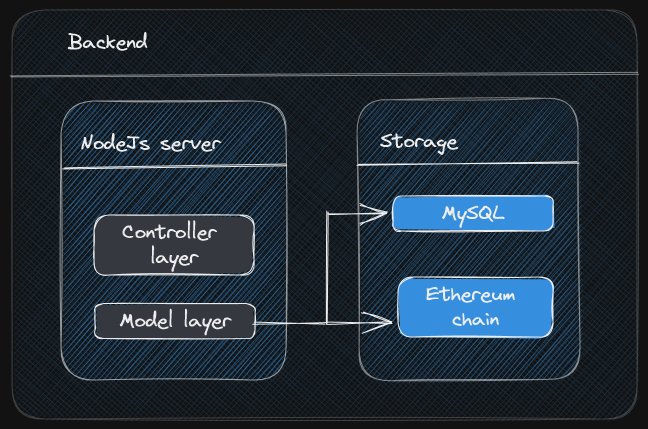
Backend
Backend is a REST server (NodeJs) with relational database behind it
(MySQL). Initially to avoid passing data as a plain text, basic auth
had been added, but now project reached the stage where is more
mature authentication mechanisms should be added, e.g. OAuth.
Also at the first stage plain parameterized sql queries had been used,
but the project reached the stage when
some kind of ORM
should be added.
After pivot some business logic like search and match queries had
been migrated to the server. It opened an issue to query both chain
and RDB to build a full aggregated response to the client. This
issue will be covered below.
To confirm stable codebase the REST API has been covered by tests.
Architecture
Contract wrappers and synthetic queries
Integration with the ethereum chain on the backend is done over
the ether.js.
I implemented a wrapper around contract api:
class Contract {
constructor() {}
getWalletWithProvider(privateKey, nodeUrl) {
let provider = new ethers.providers.JsonRpcProvider(nodeUrl)
let walletWithProvider = new ethers.Wallet(privateKey, provider);
return walletWithProvider;
}
}
class SwapChainV2 extends Contract {
constructor(privateKey, nodeUrl, contractAddress) {
super();
let swapChainAbiJson = [
"function registerUser(address user) public override",
"function getUsers() public view override returns (address[] memory)",
"function getMatches(address userFirst, address userSecond) external view override returns ((address,uint,address,uint,bool,bool)[])"
];
this.signerInstance = this.getWalletWithProvider(privateKey, nodeUrl);
this.swapChainContract = new ethers.Contract(
contractAddress,
swapChainAbiJson,
this.signerInstance
);
}
async getMatches(userFirstAddress, userSecondAddress) {
return await this.swapChainContract.getMatches(userFirstAddress, userSecondAddress);
}
async getUsers() {
return await this.swapChainContract.getUsers();
}
}
chain.getSwapValueContractInstance = function() {
let nodeUrl = `http://${config.get("chain").host}:${config.get("chain").port}`;
let privateKey = config.get("chain").privateKey;
let swapTokenAddress = config.get("chain").swapTokenAddress;
return new SwapToken(privateKey, nodeUrl, swapTokenAddress);
}
module.exports = { SwapToken, SwapChainV2, chain }
Later it the server will query database to find matches and them map this data to the data on chain:
let aggregatedModel = [];
let model = await match.getByProfileId(profileResult.id);
await Promise.all(model.map(async (matchItem) => {
let matchOnChain = await chain.getSwapChainContractInstance()
.getMatches(
matchItem.userFirstService.userAddress,
matchItem.userFirstService.userAddress
);
matchItem.chainObject = matchOnChain;
aggregatedModel.add(matchItem);
}));
The full response will be returned back to the client.
SQL query optimization
I haven't faced yet with bottleneck issues with slow queries to
the storage. However I have to think about it performance overhead
due multiple subqueries and joins.
After discussion
I ended-up with potential steps to solve improve query performance
in case I will face with it:
- Use database snapshots with slice of existing data with read-only
permissions with built-in indexes
- Use db sharding
- Pre-filter rows by distinct title and do search by them
- Use ORDER BY and MATCH for keep order during pagination and better
search options
- Consider Views and Material Views, but they might have limits on
how to perform search
- Consider to build a hash based on valuable data and do a search by
it
Mobile client
Mobile client is written on the Kotlin for Android. It has
standard, for this moment, architecture, but still follow traditional
way instead of applying Compose.
Many operations initially was done directly with the chain, but
after migration on v2 it became just 1st part of the request -
the 2nd part is to put some metadata on the server too.
Integration of the ethereum functionality pushed the project to
split up on several modules.
The stability of the codebase is confirmed over integration espresso
tests augmented by some unit tests.
Architecture
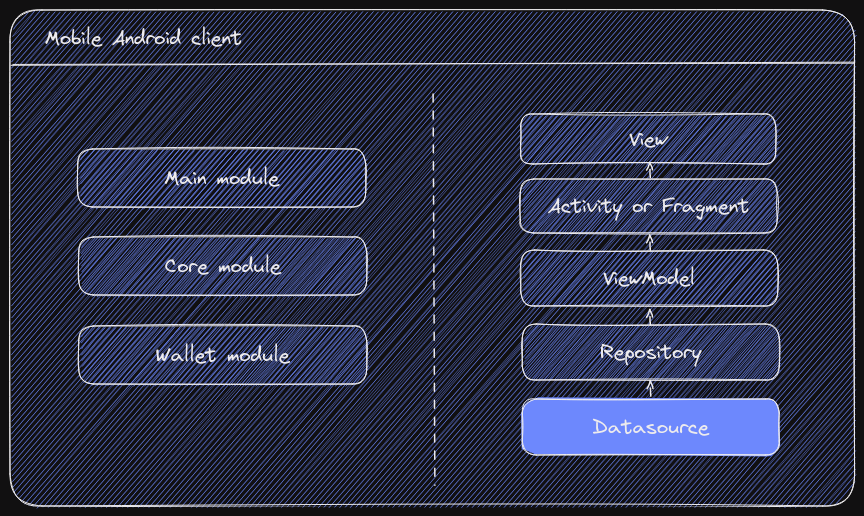
Modularization and dependency injection
Splitting monolith app into several modules usually is done to
decrease compilation time and speed up the development. For this
project it was done to improve encapsulation of business logic when
a integration with 3rd party provider become a part of backlog and
to get a hands-on experience with this architecture within a relevant
tech stack.
Current architecture has three modules as :app, :core and :wallet.
Some opinionated decisions has been made during architecture
design, e.g. IStorageRepository is obviously should be part of the
core module, but currently it is required only within wallet -
leaving it in the wallet module increases its encapsulation.
Also redesign DI to work across modules and tests brought some new
challenges, but solution had been found. I got some comment as it
could be done better, but because of neither PR or some more
information has not been shared, I do not see a way to consider it,
implement it and\or learn from it. Obviously, there is almost
always exist
a way from the solution to the best solution and from the best
to the optimal one
, so Pull Requests (PRs) are welcomed.
Web3j integration
The Ethereum dev community ported web3 on several platforms. In
Java&Kotlin&Android platform it was done under the web3j project.
I had to provide a byte code of the smart contract and implement
a Java wrapper where Java hooks trigger methods of the smart
contract.
override fun safeMint(to: String, value: Value, uri: String):
RemoteFunctionCall {
val function: Function = Function(
ISwapValue.Functions.FUNC_SAFE_MINT,
listOf(
Address(to),
value,
Utf8String(uri)),
Collections.emptyList()
)
// omit wei here as it is not a payable function
return executeRemoteCallTransaction(function)
}
Web3j allows to autogenerate such wrappers, but it doesn't work stably. I was able to manage it to work for some case and for some cases I wasn't.
Policy on dealing with a variety of tx statuses
When you write anything on chain, you call is wrapped into a
transaction which is put in the queue. Nodes with some period of
time mined transactions from queue organized into blocks. Tx is
mined as a part of a block.
When tx is in queue it has 'pending' status. After the mining it
could be either 'mined' or 'reverted'. Sometimes status 'rejected'
appeared somewhere in docs and forums, but it is not clear yet is
it the same status or some corner case.
How should mobile client deal with this different tx statuses?
The current policy of dealing with ethereum chain transactions is
follows:
- Immediate errors just shown up to the user
- Tx submitted in the tx pool, but has not been mined yet, also goes
into the client (or web server?) cache
- Each query to tx status leads to query to cache, query to chain
and update cache with the most recent data from chain (which should
trigger update on mobile client UI too)
- If tx is rejected due mining, the user is notified about it with
the most possible explanatory root cause and a prepopulated
template on tx is shown to him or her. (cached data is not removed,
but updated with either new flag or moved to the different table)
Pivot to a background pooling and the WorkManager
Keeping the same data on chain and on the server brings the issue
of complete and relevant data. Is it on the server? Is it on the
chain? We use chain as a source of non reversible information,
therefore data on chain is considered as primary data.
However chain operations might take a long time and not always will
end up successfully. At this moment, on the Goerly test network a
single transaction takes near 10 hours. Private self configured
chain process transaction within 15 seconds, but I could not be sure
it would be the same speed after several years of intensive usage or
after possible changes in configs to launch in the production.
How to solve this issue?
Taking into the account all these thoughts above each operation
from the mobile client should go to the chain. For the end user it
might look like a pending transaction. From the tech side tx is
cached, tx is waiting for its turn on the chain and when it is
mined the mobile client receives a result or the mobile client just
query chain to get the status of this transaction. When tx is
successfully mined, the client performs a POST request to the
backend making this token available for main business operations.
There are known changes in foreground service behavior which should
be taken into account for long-running operations:
Foreground services official docs
Known changes
The current official way to execute such scenario is to use
WorkManager. It is a cause behind the project 2nd pivot to migrate
a part of functionality from the coroutines to WorkManager.
Workers encapsulates background operations and put its results into
the cache. At the app launch, background pooling is started which
listens a queue with pending transactions to run corresponding
request to the server. This queue is automatically updated each
time when cache layer is updated.
Integration tests
To confirm codebase stability I use UI integration tests which is
done over Android official tool Espresso.
On the top of it I actively use a Robot pattern which I learnt
over work with the Pivotal team (which they learnt from an one
Google conference).
The idea is to see a test like a web crawler checking a wep page.
The test logic is encapsulated within a special class which methods
emulates actions user-like behavior:
class ProfileRobot {
fun seesName(name: String): ProfileRobot {
onView(withId(R.id.name))
.check(matches(ViewMatchers.isDisplayed()))
.check(matches(withText(containsString(name))))
return this
}
fun seesContact(input: String): ProfileRobot {
onView(withId(R.id.contact_phone))
.check(matches(ViewMatchers.isDisplayed()))
.check(matches(withText(containsString(input))))
return this
}
// ...
fun enterCustomDebugData(name: String, phone: String, secret: String, wallet: String) {
onView(withId(R.id.name))
.perform(ViewActions.replaceText(name))
.perform(ViewActions.pressKey(KeyEvent.KEYCODE_ENTER))
/*.perform(typeText(query), pressKey(KeyEvent.KEYCODE_ENTER)) // Unicode chars is not supported here */
onView(withId(R.id.contact_phone))
.perform(ViewActions.replaceText(phone))
.perform(ViewActions.pressKey(KeyEvent.KEYCODE_ENTER))
onView(withId(R.id.secret))
.perform(ViewActions.replaceText(secret))
.perform(ViewActions.pressKey(KeyEvent.KEYCODE_ENTER))
onView(withId(R.id.wallet_address))
.perform(ViewActions.replaceText(wallet))
.perform(ViewActions.pressKey(KeyEvent.KEYCODE_ENTER))
}
}
Later it is called from an UI test which makes test suite concise and easy to maintain:
@Test
fun onStart_whenServerIsTurnedOffEnterDebugDataAndSubmit_seesErrorDialog() {
val activityScenario = ActivityScenario.launch(MainActivity::class.java)
dataBindingIdlingResource.monitorActivity(activityScenario)
robot.clickDebugButton()
robot
.seesName("Dmitry")
.seesContact("+79207008090")
.seesSecret("pwd")
.seesWalletAddress("0x62F8DC8a5c80db6e8FCc042f0cC54a298F8F2FFd")
.clickSubmitButton()
robot.seesErrorDialog("Something went wrong")
activityScenario.close()
}
What is next
This part covers general overview of the Swap mobile and backend
implementation. Part 1 covered a smart contracts
integration and Part 2 covered a smart contracts
test coverage.
The next, final, publication will cover test and deployment automatization.
One related post:
Principles behind my work
Open web app used for architecture diagrams:
Excalidraw